Схема дистрибуций слов

Ввиду ограниченности текста с целью получения полной дистрибуции (не только реально зафиксированной, но и принципиально возможной) необходимо применение метода субституции и опроса информанта (носителя языка).
После проведения такого эксперимента мы можем получить следующее разбиение слов на классы:
| А: | группа | Б: | характеризоваться |
| признак | и другие классы | ||
| класс | именоваться | ||
| язык | принадлежать являться |
Рассмотрим на примере класса А примерную процедуру получения моносем.
Класс А: Слова "группа" и "класс" имеют тождественные полные дистрибуции и признаются представителями одной моносемы.
Дистрибуции слов "группа" и "признак" различаются только не вхождением слова "признак" в словосочетание "... с признаками". Кроме того, в этом словосочетании замена "с признаками" на "с группами", "с классами", "с языками" делает это словосочетание семантически не отмеченным для всех слов класса А.
Дистрибуции слов "язык" и "признак" характеризуются наличием отмеченного словосочетания "языки происходят" и отсутствием такового у слова "признак". То же относится и к слову "группа". Кроме того, от слова "группа" слово "язык" отличается отсутствием отмеченного словосочетания "группа языков".
Таким образом, "диагностирующими" словосочетаниями (в более широком контексте обычно говорится не о словосочетаниях, а о классах словосочетаний) являются следующие (знаком а обозначается элемент словосочетания, который может заменяться словом класса А):
Представим на следующей таблице плюсами вхождение в эти словосочетания слов класса А:
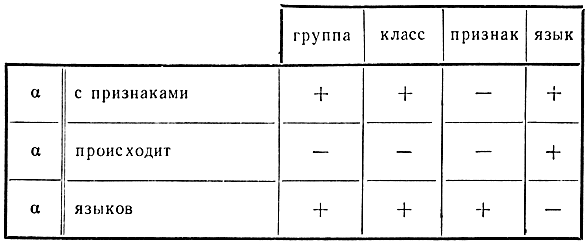
Таким образом, мы получаем на основе анализа класса А (включающего слова, функционально достаточно близкие и противопоставленные по дистрибуции всем другим словам) три моносемы "группа-класс", "признак", "язык", семантически дифференциально различающиеся.
Анализ дистрибуции слова "основа" и проведение несложных операций, сходных с теми, что проделывались с "классом", "языком", "признаком", приводит к выделению моносемы "на основе".
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://genling.ru/ 'Общее языкознание'